Machine Learning vs LLM: Differences, Applications & Impact
Artificial intelligence (AI) is the broad field focused on creating machines capable of mimicking human intelligence, encompassing tasks like reasoning, decision-making, and perception. Within artificial intelligence, machine learning (ML) is a key subfield that enables systems to learn from data, while large language models (LLMs) are advanced technologies built on top of machine learning, particularly deep learning. What are the differences of ML Vs LLM?
LLMs like GPT are built on decades of progress in machine learning, specifically in a subfield called deep learning. But what exactly makes these systems different from earlier ML models, and why does it matter?
This article walks through the basics, answering how Machine Learning works and how Large Language Models (LLMs) fit into the picture. Along the way, we’ll see how LLMs differ from traditional models in size, architecture, training, and capabilities.
Introduction. What is Machine Learning?
Machine Learning (ML) is a broad field of artificial intelligence (AI) that focuses on developing algorithms capable of learning patterns from structured or unstructured data to make predictions. AI systems, including those that use ML, are designed to mimic aspects of human intelligence, such as reasoning, decision-making, and problem-solving. The ML algorithms run on standard hardware, from laptops to GPUs and TPUs. ML encompasses a range of approaches, from basic statistical methods to complex neural networks.
ML is used for a wide range of tasks such as classification, regression, clustering, and forecasting, while Large Language Models (LLMs) are a specialized branch focused specifically on understanding and generating human language.
ML systems generally:
- Process training data to find patterns
- Create models that represent these patterns
- Use models for predictions or decisions on new data.
Core Paradigms of Machine Learning
Supervised learning is a category of machine learning in which an algorithm is trained on a dataset that includes inputs and their corresponding known outputs. Each training example is a pair: an input vector and its associated label or target value. The system learns to map inputs to outputs by minimizing the error between its predictions and the true labels. ML thrives on task-specific, labeled data. This approach is used to solve two main problems: classification and regression.
- In classification tasks, the goal is to assign inputs to one of several predefined categories: for example, identifying whether a financial transaction is legitimate or fraudulent or detecting objects in an image.
- In regression tasks, the objective is to estimate continuous values, such as forecasting electricity demand, predicting stock prices, or assessing the remaining useful life of an engine.
Anomaly detection is a task in ML that identifies unusual patterns or outliers in data sets.
ML models are trained to perform specific tasks, such as predicting customer churn or the likelihood of fraud.
Unsupervised learning operates without answer keys, like exploring a city without a map. The algorithm finds natural relationships in unlabeled data. Recent advances enable it to learn by comparing data views, often performing nearly as well as supervised systems with only 1% of labeled examples.
Reinforcement learning differs in that it learns through trial and error and feedback rather than from examples. Similar to training a pet: reward good behaviors to encourage actions leading to treats, and algorithms develop strategies to maximize rewards. While successful in games like chess and Go, real-world challenges include continuous movements, incomplete information, and delayed or scarce feedback.

Algorithmic Foundations of Machine Learning Models
Machine Learning encompasses many algorithms and models, including traditional models like Naïve Bayes and complex ones like neural network-based models. Many traditional ML algorithms, such as logistic regression and decision trees, are discriminative models designed for classification and prediction tasks. These models focus on classifying data instead of generating it. The shift from classical statistics to ML reflects evolving modeling approaches and greater computational power.
ML models like decision trees are easy to interpret, providing clear decision paths, whereas LLMs are generally complex and require more rigorous evaluation to understand their outputs.
- Linear models solve convex optimization problems with guaranteed outcomes, while tree-based methods partition the feature space using information gain to capture non-linear boundaries without relying on gradients.
- Support Vector Machines (SVMs) work by finding the optimal boundary between different data classes.
- Deep Learning is based on deep neural networks that leverage hierarchical representations, with each layer transforming its inputs to increasingly abstract features. Their function approximation properties enable the modeling of complex relationships. Specialized neural architectures, such as 3D CNNs (3D Convolutional Neural Networks) and attention mechanisms (which dynamically weigh inputs), efficiently process textual data and images. These techniques improve computer vision and natural language processing, where machine performance now matches human abilities in specific areas.
What are Large Language Models?
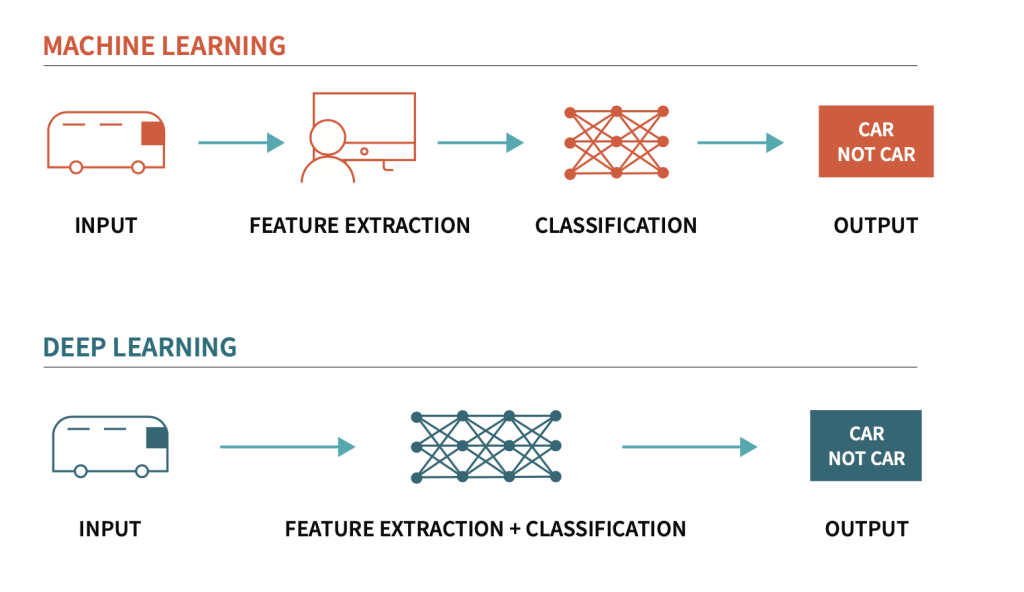
LLMs are a type of deep learning model and a specific class of generative AI models focused on language generation. They are designed to generate language and produce human-like text, conducting conversations, summarizing content, and more. LLMs utilize deep transformer architectures with billions of parameters, far exceeding the thousands to millions of parameters found in many traditional ML models. In exchange, they require vast and diverse datasets, huge compute resources, and careful fine-tuning to align outputs with intent. Recent advancements have transformed LLMs from passive responders to active agents capable of autonomously executing complex multi-step tasks, marking a significant shift in AI capabilities.
LLMs represent a significant advancement in natural language processing. While traditional Natural Language Processing relied on hand-crafted features and task-specific architectures, LLMs employ self-supervised learning on vast text corpora to develop general-purpose language understanding capabilities.
LLMs use transformer architectures with self-attention mechanisms to model relationships among words in long sequences, capturing context and meaning.
Attention is a vector of significance weights used to gauge correlation with other elements to predict a pixel or word. The sum, adjusted by the attention vector, approximates the target. An LLM transforms input tokens, e.g., x₁, x₂, …, xₜ₋₁, into a probability distribution for the next token, like in the example: "The pressure drops when the valve…" where P(“opens”)=0.78, P(“fails”)=0.15, P(“heats”)=0.07.
The LLM estimates these probabilities through statistical language modeling: it’s not reasoning about pressure or valves.
In reality, whether the pressure drops or rises when a valve opens depends on the pressure difference across it. But the model completes the sentence with what’s most statistically common in its training data.
That’s how LLMs generate text: by predicting one token at a time based on likelihood, not physical laws.
Hallucination and Confabulation in LLMs
LLM hallucinations occur when models generate false claims (e.g., stating "One pound of air weighs more than one pound of water") due to:
- Data gaps: Training on incomplete/biased corpora
- Overfitting: Prioritizing linguistic patterns over factual accuracy
- Prompt ambiguity: Unclear inputs triggering "best guess" outputs

Confabulations occur when LLMs produce plausible but incorrect responses, often misleading in critical situations. For example, an LLM might say “Canberra' for Australia's capital but later incorrectly state “Sydney,” showing inconsistency. These errors show that LLMs generate info from patterns, not facts. Hallucinated outputs tend to be more narrative than factual, resembling storytelling, which could be useful in creative writing if understood as fictional.
Despite advances, challenges remain: a lack of physical experience for common-sense reasoning, accuracy that depends on training data, and difficulty tracking long dialogues.
Machine Learning Vs LLM - Key Differences
Machine Learning (ML) is a broad field used for classification, regression, clustering, and forecasting across many domains, typically producing numerical results or classifications, whereas LLMs are a specialized branch focused on understanding and generating human language. LLMs interact through prompt engineering, which allows users to guide their output in natural language.
Traditional ML often requires retraining to adapt to new tasks, whereas LLMs are highly flexible and capable of zero-shot learning.
In practice, organizations often combine both ML and LLMs rather than choosing just one.
ML Vs LLM: Data Requirements, Model Complexity, Training, and Resources
ML can work with structured data or small datasets. On the other hand, LLMs require enormous volumes of text, billions or trillions of tokens, to learn linguistic patterns effectively.
ML models have long relied on feature extraction for applications across various industries.
The burden of complex feature extraction is shifted to financial costs when using LLMs.
LLMs use deep transformer architectures with billions of parameters. In contrast, many ML models, such as decision trees and logistic regression, are more straightforward to interpret.
Training an LLM demands massive compute resources (GPUs, TPUs, distributed systems). Traditional ML models can often be trained on standard hardware in less time and at lower cost.
The above considerations on ML Vs LLM are summarized in the table.

Applications of Machine Learning and LLMs
Machine Learning (ML) enables computers to learn from data patterns without explicit programming. By creating predictive models based on past results, ML reduces computation time in fields like engineering simulation, including CFD. It is particularly beneficial when physical models are too costly or complex to solve directly. ML is versatile and applicable to classification, regression, and optimization. This explains the rise of applications of Machine Learning in engineering. However, ML often requires manual feature engineering: selecting and transforming the appropriate input variables to achieve good results. This step can be time-consuming and may limit scalability.
In finance, ML models flag suspicious transactions in real time by recognizing subtle deviations from normal behavior. In e-commerce and entertainment, recommendation engines learn users' preferences to serve relevant products or content, improving engagement and conversion rates.
In healthcare, ML supports diagnosis by analyzing medical scans or lab data with a precision that complements clinical expertise. Logistics and supply chain operations use ML to anticipate demand fluctuations, detect bottlenecks, and improve inventory decisions.
ML also powers autonomous systems, enabling vehicles, drones, and robots to interpret sensor data, adapt to dynamic environments, and operate safely with minimal human input, thanks to Machine Learning optimization of the project parameters.
Applied LLMs and the Turing Test
Large Language Models (LLMs) have changed how we interact with technology. They produce outputs that often mirror human language with remarkable fidelity. Mention that LLMs are trained on vast amounts of internet text, enabling them to understand and generate human-like text. This advancement has sparked significant discussion about their capabilities, especially in the context of the Turing Test, a benchmark for machine intelligence.
LLMs like OpenAI's GPT-4.5 can generate text that is not only coherent but also contextually relevant. For instance, GPT-4.5 is used to draft articles, compose poetry, and handle customer service interactions. Mention that Large Language Models can automate content creation processes, saving time and resources for businesses. Users have reported that the responses are often indistinguishable from those written by humans, noting the model's adeptness at understanding nuanced prompts and delivering appropriate replies.
Also mention that the speed at which AI models respond, known as latency, is critical in user-facing applications.
LLMs are preferred for language tasks such as chatbots and summarization, but they raise concerns about the spread of misleading information and their deceptive use. Balancing utility and ethics remains a key area of discussion.
The Turing Test and LLM Consciousness
The Turing Test checks if a machine shows human-like intelligence. A human evaluator interacts via text with a person and a machine, unaware of which is which. If the evaluator can't distinguish the machine from the human, the machine passes. The focus is on convincing responses, human-like language, reasoning, and conversation, not just correctness. The test assesses behavior, not genuine understanding of consciousness.

Recent tests show GPT-4.5 was judged human 73% of the time, surpassing actual humans in perception. This is the first empirical evidence of an AI passing a traditional three-party Turing Test. These results spark debates about machines achieving human-like interaction. Some see it as progress, while others caution that mimicking language doesn't mean genuine understanding or consciousness. LLMs have transformed many sectors, offering highly accurate human-like text. However, these advances raise ethical concerns about misuse and the need for transparency in AI-human interactions.
Integration in Engineering Workflows
ML, especially Deep Learning, can accelerate simulations, optimize designs, and predict physical behaviors from data.
Neural Concept operates as the intelligence layer for engineering: the 3D Deep Learning approach processes realistic product geometries directly, connecting CAD, simulation, and PLM into a single AI-native environment.
Meanwhile, LLMs can assist in automating documentation, interpreting results, generating code, and supporting decision-making through natural language interfaces.
Combining both offers an intriguing synergy: ML handles numerical tasks and design predictions, while LLMs enhance usability, explanation, and interaction. For example, engineers can query simulation results in natural language or receive design suggestions from fast ML-driven models. This duo reduces manual effort, accelerates iterations, and makes complex tools more accessible.
Future Trends and Conclusion
Future Trends - Generative AI
Generative AI refers to a broader category of AI systems capable of creating content such as text, images, and videos. It relies heavily on deep learning techniques, particularly Deep Neural Networks, which automate and enhance feature extraction from unstructured data. With AI data collection and generation, generative AI can help businesses automate content creation and achieve scalability without compromising quality.
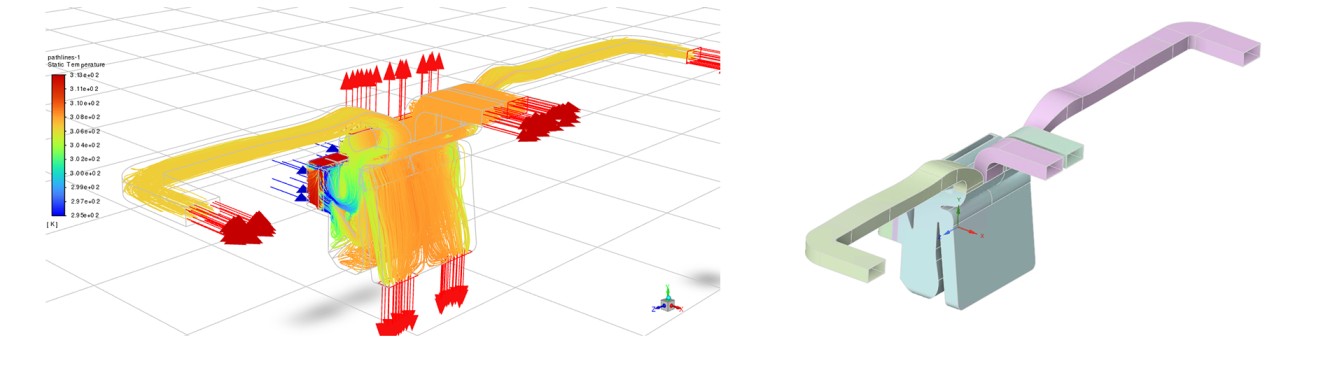
Generative AI can be backed by "serious" engineering predictions, such as those from applying Machine Learning in CFD, as shown by Neural Concept's use cases.
Large Language Models (LLMs) specializing in language tasks are a key part of this generative trend. LLMs and generative AI are built on neural networks, but their applications are expanding rapidly, from creative tools and chatbots/virtual assistants to code generation and simulation. Companies employ LLMs to develop intelligent chatbots that enhance customer service by providing quick, accurate responses, as these models are advanced machine learning systems designed to process and generate text.
We're seeing a shift in the roles of ML and LLMs. Traditional Machine Learning models are often more efficient in structured data analysis, and ML continues to excel at structured prediction and decision-making tasks. LLMs and generative models will take on more complex, creative, and human-facing functions.
Conclusion
While LLMs are a subset of machine learning, they represent a significant leap in scope, scale, and application.
Traditional ML techniques are optimized for structured data, interpretability, and specific tasks like classification or forecasting.
LLMs use vast datasets, deep transformer architectures, and large computational resources to model human language flexibly. They excel at translation, summarization, and dialogue but rely on statistical likelihood, which can lead to convincing yet inaccurate responses, especially with ambiguous prompts or limited data.
For engineers, ML tools are great for numerical modeling and decision-making, offering interpretability and efficiency.
LLMs are best seen as advanced linguistic interfaces for drafting, querying, or exploring ideas, but not as infallible sources.
Understanding these differences will help you select the right tool and manage risks.
FAQ
How does domain expertise help in a machine learning pipeline?
It guides feature engineering and model design, improving accuracy, especially for structured data problems such as binary classification.
What makes deep learning solutions suitable for multiple tasks?
Their feature extraction capabilities enable them to handle structured and text data, as well as generative AI use cases, from a single pre-trained model.
How is nuanced language understanding used in sentiment analysis models?
It helps capture nuanced linguistic patterns, which are crucial when analyzing text data from diverse datasets in natural language processing tasks.
Why are technical and financial considerations important in executing financial trading algorithms?
Both the training data and model choice, such as using deep learning for structured data, affect performance and risk in real-time scenarios.
What powers modern virtual assistants?
Pre-trained models trained on diverse datasets with strong language understanding, enabling them to manage tasks from answering queries to managing emergency response systems.
When do LLMs outperform classical ML models, and when does classical ML win?
LLMs excel at unstructured data tasks like text generation, semantic reasoning, and nuanced language understanding. Classical ML wins on tabular, structured data problems where training data is limited, latency is critical, or interpretability is required.
How does the interpretability of traditional ML models compare to the black-box nature of LLMs?
Traditional models like decision trees or logistic regression expose their reasoning directly, making them auditable and defensible to regulators. LLMs operate as black boxes: their predictions emerge from billions of parameters with no accessible decision path.
Can LLMs perform traditional machine learning tasks like regression or classification?
Yes, but inefficiently. Fine-tuned LLMs can handle binary classification tasks and sentiment analysis models, but they consume far more compute than purpose-built classical ML models trained on equivalent structured data.
How do ML and LLMs compare for predictive maintenance in manufacturing?
Classical ML models trained on sensor time-series data outperform LLMs in this task. The task is a structured data problem with clear numerical features; LLMs add latency and cost without improving accuracy.
How do ML and LLMs compare for finance use cases such as risk modeling, fraud detection, and customer support?
Risk modeling and fraud detection favor classical ML, where structured data, auditability, and speed matter. Customer support and document analysis benefit from LLMs, where nuanced language understanding and generative capabilities drive value.
Should healthcare applications use LLMs or traditional ML models for clinical decision support?
It depends on the input. Diagnostic models working from lab values and imaging features perform better with classical ML. LLMs add value in summarizing clinical notes or navigating unstructured patient records, though interpretability and liability concerns apply to both.
As a data scientist, when should I prototype with an LLM versus classical ML first?
Start with classical ML whenever the problem involves structured data, a well-defined label, and a modest dataset. Reach for an LLM when the input is text, the task requires reasoning over context, or no labeled training data exists and a pre-trained model can be prompted directly.