AI Models — Data Collection and Generation
Since the advent of the first steam engine, industries have been searching for ways to improve their processes. The Darwinian evolutionary nature of economic competition drives this unending pursuit. Promoting new technological advances is the best way to stay ahead of the curve. Artificial intelligence (AI) has emerged as a powerful advance in recent years. Like it or not, AI is here to stay! So we should embrace it - or at least understand its implications to become able to drive its applications.

A key AI application in the automotive industry is the development of predictive models. Predictive analytics can help companies make informed decisions about their products and processes. These models are often built using Machine Learning algorithms. However, Machine Learning (ML) usually requires large amounts of data to be trained.
Therefore, a perceived limitation exists when deploying ML methodologies in automotive companies. It is about the data available to train the AI model. Collecting and managing this data can be a challenge for many engineering teams.
In this article, we will show some data collection and management practices. This can help companies to build an accurate and reliable AI model. This helps to drive innovation and progress in the automotive industry.
What Is an AI Model?
For this article, an AI model is a mathematical representation of a problem or task developed using ML (Machine Learning) algorithms. It is essentially a program that learns from data and makes predictions or decisions based on that learning of the correlation between input and output data.
AI models can be trained on large datasets (collections of samples, each representing a data point of input and output) and used to classify data or (as the focus of our article) perform exciting tasks such as making predictions and assigning predicted outcomes for new incoming data (new inputs).
AI and ML Models
Artificial intelligence and ML models are closely related but differ in their scope. Artificial intelligence is a broad terminology encompassing many technologies, including machine learning. Machine learning is a subset of AI that focuses on building models to learn from data and make predictions or decisions based on that learning. In other words, all ML models are AI models, but not all AI models are ML models. How to deploy these models?
Deployment of an AI Model
Deploying an AI model involves making the model available for use in real-world applications. This typically involves packaging the model as a software component that can be integrated into other systems or applications. Deploying models can also involve testing and tuning the model to ensure it performs accurately and efficiently.
AI models are becoming increasingly important in various applications, from business and finance to healthcare and transportation. They can help organizations to make more accurate predictions, automate repetitive and complex tasks, and improve decision-making processes. The ability to develop and deploy an AI model is becoming a critical competitive advantage for businesses and organizations.
How models are collected can represent a significant difference between organizations with access to the ML prediction potential and organizations that stop at the "proof of concept" level.
AI Models and Data Collection Process
The data collection process is a crucial component of building accurate artificial intelligence models. To ensure that data is of high quality, companies must first identify the data sources and determine the required data type.
Data sources can be internal or external, structured or unstructured, and include text and images in 2D or 3D. Once data sources are identified, the next step is to collect the data in a way that is efficient, accurate, and secure; also, engineers must ensure data are unbiased and representative of the population being modeled.

To achieve this, engineers use a variety of data collection methods.
Another method is to use AI-generated data. This involves using AI models to generate synthetic data similar to real-world data. This method is beneficial when a limited amount of real-world data is available or when collecting real-world data is difficult or expensive. However, this method has limitations and can produce biased data if not done correctly.
Another method is to collect data from external sources, such as social media, web scraping, or online surveys. This is not suitable for the engineering applications we have in mind.
One method is to collect data from existing data warehouses and system integrators (technological partners) with the problem of data ownership arising (who will own the data, and who will own the predictive analytics model arising from AI?)
Collecting data from existing internal databases, such as the company PLM, is a secure method of ensuring an intellectual property.
This method is, however, limited by the quality and quantity of data available.
Data Processing and Cleaning
Data collection is only one part of building accurate AI models. Once data is collected, it must be preprocessed and cleaned to remove any noise or errors. This involves transforming the data into a format that AI models can use. This is where 3D Deep Learning based predictive models have an advantage. Since they use raw 3D CAD and CAE data, they can skip the preprocessing step, saving time and effort.
AI Algorithms
After data preprocessing, the next step is to select the appropriate AI algorithms to build the predictive models. The algorithm choice depends on the data type used and the desired outcome.
Some commonly used algorithms include:
- decision trees,
- logistic regression,
- support vector machines (SVMs),
- Neural networks (we will talk more about neural network architectures)
Once the model is built, it must be validated and tested to ensure accuracy and reliability.
In conclusion, data collection is critical to building accurate and well-defined AI models.
Machine Learning in the Automotive Industry
The automotive industry is leveraging artificial intelligence (AI) models to significantly improve in various areas, including design, engineering, manufacturing, and distribution. A significant challenge in deploying AI models in the industry is the need for extensive training datasets to develop accurate predictive models. Training existing models efficiently on the Cloud and general optimization of computing resources is one of the present challenges in this industry.
Classic Machine Learning Models and Limitations
Classical machine learning models, such as linear discriminant analysis and the logistic regression model, have been widely used in the automotive industry for predictive analysis. For instance, these models can predict the likelihood of a car failure or crash based on independent variables such as speed, weather conditions, and driver behavior.
However, these models can be limited in their accuracy and scope due to their reliance on specific data set parameters: specialists in mathematics and data science have therefore developed deep neural networks that can handle a broader range of input data.
AI and Image Recognition in the Automotive Industry
Deep neural networks can be trained to recognize patterns in these different data sources, allowing the autonomous vehicle to make decisions based on the combined information.

The predictive capabilities of the AI models can be constantly enhanced, improving the accuracy of predictions and making the autonomous vehicle more responsive to changes in its environment.
Limitations of Classic Machine Learning Approaches
We have previously hinted that developing and implementing deep networks can overcome the limitations of classical machine learning models in the automotive industry. These deep learning models can handle a broader range of input data, allowing for more accurate predictive models that adapt to changing conditions.
Classic machine learning models, as we have seen, are designed to be trained on specific data parameters, and this can limit the diversity of data that can be collected to train a single supervised learning model.
A new predictive model must be built from scratch for each new program, and the model training dataset must be re-generated at each new design campaign.
To address this drawback, a specific class of AI models called 3D Deep Learning-based predictive models are being used in the industry.
Deep Neural Networks
Data scientists have developed deep neural networks, a specific class of artificial neural networks and intelligence models that can handle diverse data provided as input. Deep learning models use advanced data analysis techniques to identify patterns in the data. The model can be trained across many geometrical parametrizations and topologies, allowing for a much larger pool of training data.
The flexibility of deep networks enables data scientists to develop models that can be used across various topologies and parametrizations.
Developing deep networks has dramatically improved the capabilities of AI models in the automotive industry. They offer a more flexible approach to data collection and analysis, allowing for a larger pool of training data to be used to develop predictive models.
CAE Simulation
CAE stands for computer-aided engineering, which uses computer software to simulate the behavior of physical systems, thus solving complex problems in 3D. CAE has become increasingly relevant for Industry 4.0 due to the concept of digital twins.

Any simulation result from any computer-aided engineering (CAE) team can be recycled by deep learning. This reduces the effort needed to collect data and enhances the flexibility of the AI models.
CAE and Data Generation
A key advantage of CAE is its ability to generate vast amounts of data that can be used to develop AI models. These data sets can be used to train machine learning algorithms and develop predictive models that can be used to optimize product designs, improve performance, and reduce costs.
Enter Machine Learning with Convolutional Neural Networks
Deep networks such as those developed by Neural Concept (Convolutional Neural Networks = CNNs) are particularly well-suited for working with data generated by CAE simulations. The AI model is very similar to that in image processing (computer vision). The CNN AI model can handle large volumes of complex data, such as 3D CAD and CAE data, and are entirely agnostic for specific parametrizations of designs. Therefore CNNs can provide an AI-driven simulation platform as a supplement for CAE or even as a choice for designers.
This means the same model can handle complex problems and be trained across many geometrical parametrizations and topologies, making it much more flexible.
Moreover, CNNs can learn to recognize patterns and relationships in the data, allowing them to make predictions and generate new designs based on the data.
In conclusion, combining CAE simulations and CNNs is a powerful tool for developing AI models in the engineering industry. By reusing simulation results from CAE teams, data scientists can significantly reduce the effort needed to collect data and enhance the flexibility of the AI models.
This can lead to more efficient and cost-effective product designs and ultimately improve the performance and safety of the products.
3D Deep Learning Predictive Models
Companies must implement data management workflows to build accurate and well-defined AI models as the industry increasingly adopts AI-based design workflows. A perceived limitation in deploying AI methodologies in automotive companies is the amount of data available to train predictive models.
While Machine Learning benefits greatly from large datasets, collecting these datasets can sometimes be seen as a significant obstacle by engineering teams to deploy predictive models at a large scale. This can be alleviated by a specific class of AI models: 3D Deep Learning-based predictive models.
These models use raw, 3D CAD, and CAE data and are entirely agnostic to any specific parametrization of designs. This means that the same can handle and be trained across many geometrical parametrizations and topologies, benefiting from a much more extensive data pool.
Ultimately, any simulation result from any CAE team can be re-used inside these models, making them much more flexible and, thus, drastically reducing the effort needed to collect the data.
Transfer vs Traditional Approach: General Principles
Before going into the details of an automotive application, we will make some general considerations on data usage efficiency. Classical AI models rely on a very specific parametrization to be trained. Let us imagine a particular "Project" like a car model without a spoiler defined as a set of lengths, thicknesses, radii, etc. The input and output variables can be correlated with an inference model (AI-based predictive analytics model), also known as a surrogate, being an emulation or surrogate of a computer-aided engineering (CAE) model that provided the data points. Although more sophisticated than a linear regression model, the regression model will be specialized to the "box" of project parameters.

This means that these popular AI models cannot be used across topologies or parametrizations, limiting the diversity of data that can be collected to train a single model to perform specific tasks. Therefore with two (or more) projects, we would obtain a series of "siloed" surrogates, like in the figure.
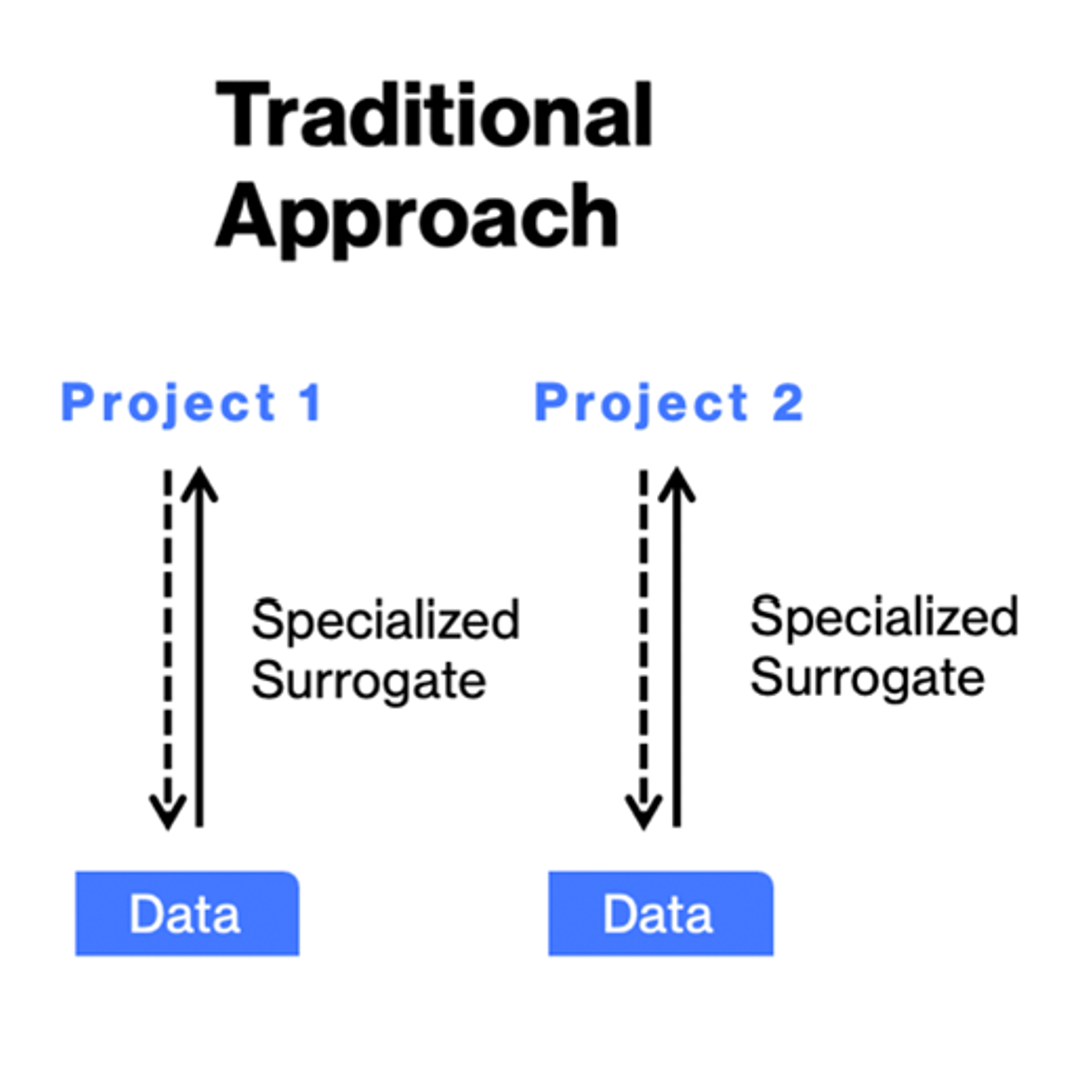
More specifically, a new predictive model must be built from scratch for each new project, and the dataset must be re-generated at each new design campaign. This siloed approach restrains the range of suitable applications within the automotive industry.
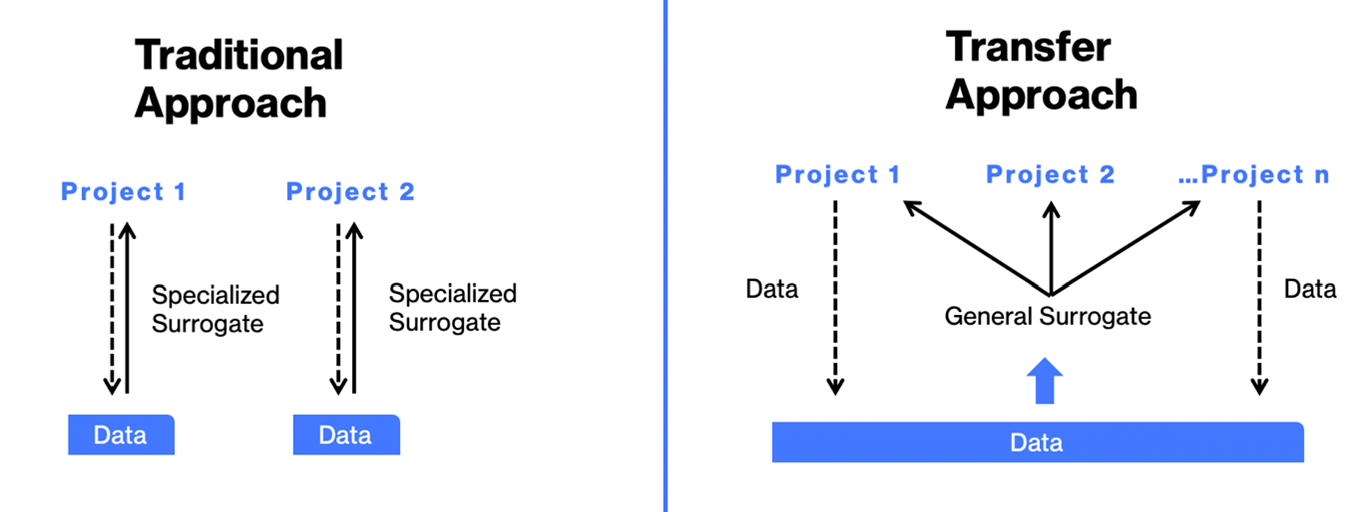
Measuring the Benefits of the Transfer Approach
The new Transfer Approach by Neural Concept provides an exciting perspective for companies across all industries, starting from the automotive sector, because the 3D Deep Learning cross-project cumulative approach, as the figure shows, began to be more efficient (n° of needed simulations per project) already with two programs (projects) per year.
Although heuristic, the figure (based on Neural Concept experiences over the last years) has deep business implications because it discriminates between the red line of overinvestment and the blue-green line of data efficiency of the new deep learning approach.
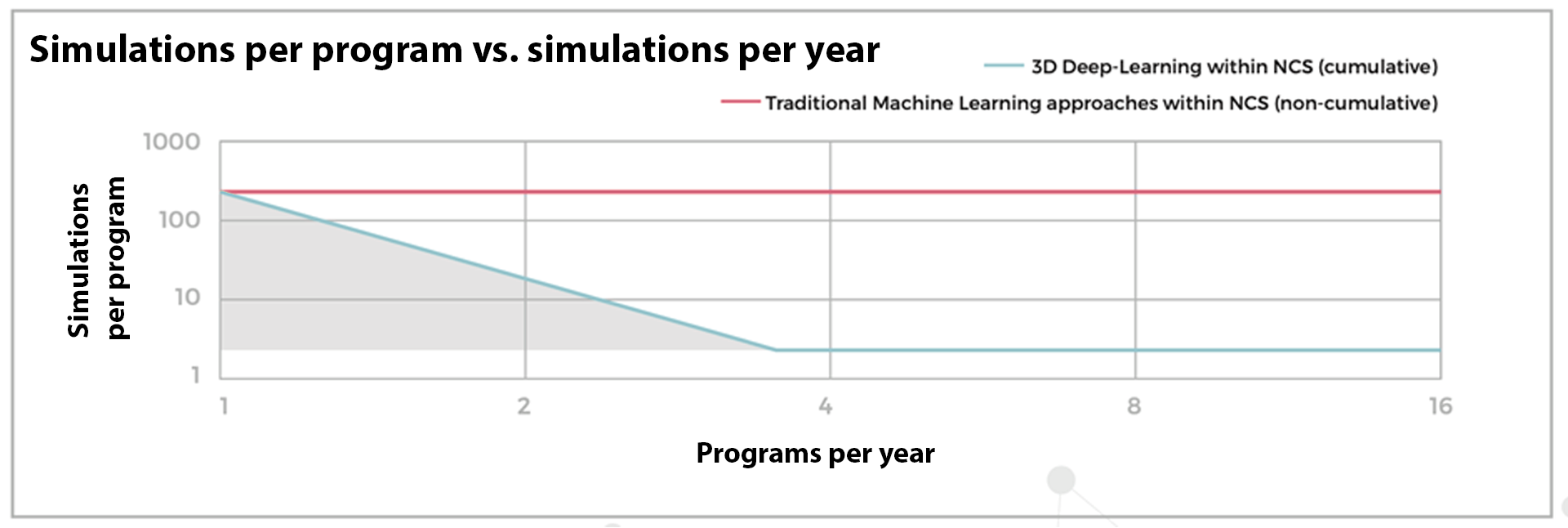
We will now implement what we have learned in a practical use case for the automotive industry.
Development of HVAC System and Data Collection for AI Model
An automotive HVAC system, or Heating, Ventilation, and Air Conditioning system, regulates a vehicle's temperature, humidity, and air quality. An automotive HVAC system ensures passenger comfort and safety during weather conditions, including a heater core, evaporator core, compressor, refrigerant, and blower motor. They can all be modeled with CAD and CAE, thus providing a dataset for AI models built as neural network analytics tools for designers' engineering predictions.

Case Study: HVAC
Let us combine all the previous ideas into a concrete example from the automotive industry, namely in HVAC development.
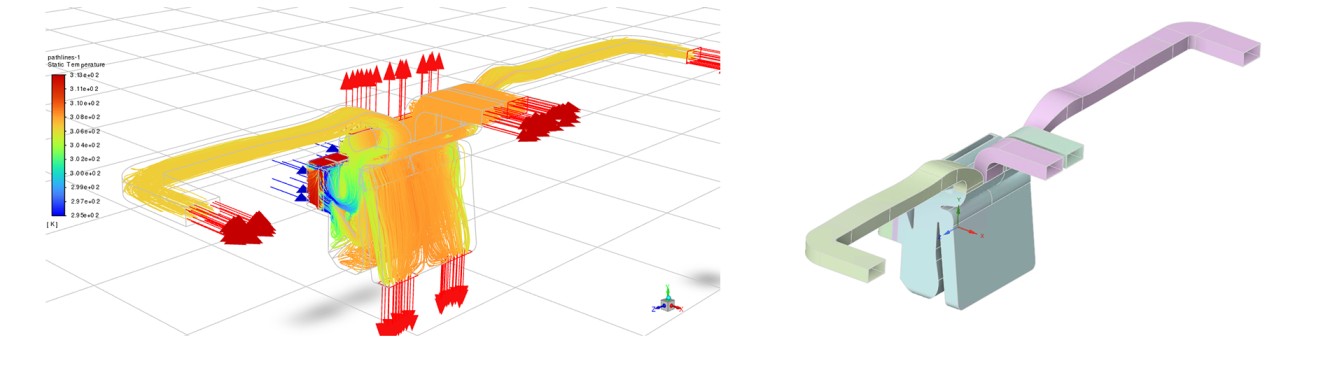
We assume that the Climate Control team of a Tier 1 provider to a large automotive company has stored design iterations and simulation results for their past five HVAC programs (projects).
Design and R&D teams usually perform between 20 and 40 design variations within these projects. If we could put together all the teams' work, we would have approximately 150 designs and corresponding CFD runs that could be used to train a Machine Learning model. These five HVAC projects, however, have different CAD parameterizations, and their topologies differ broadly as they correspond to various vehicle types.
The image shows a second project, uncorrelated to the second one, regarding geometry parametrization because it was designed by a different team with different constraints, including the possibility of servicing a different customer (an OEM).
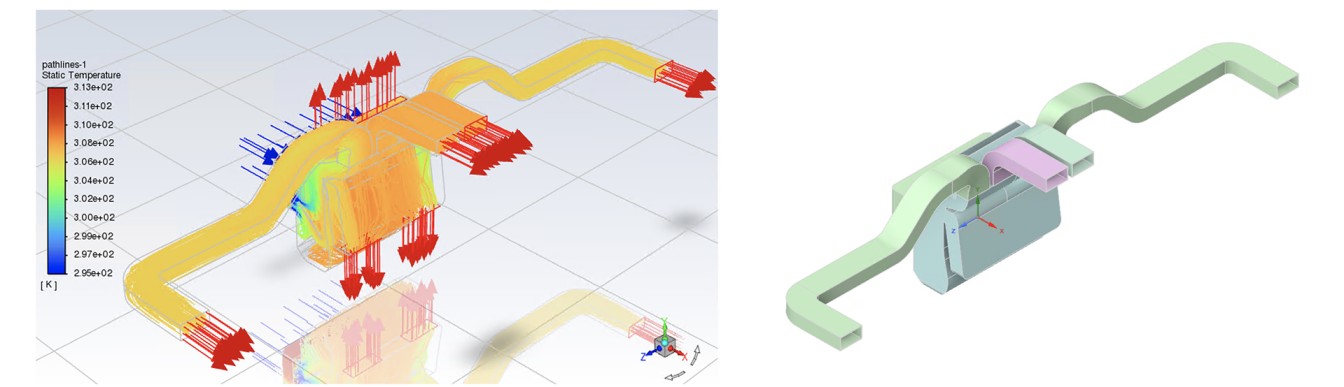
With standard, parameter-based Machine Learning approaches, a new surrogate model should specifically be built for each project. Therefore, the engineering computer science team could not use this same AI model for the next project. Moreover, within each project, the ~20-40 CFD simulations would be insufficient to train an accurate surrogate model. The outcome would be a collection of inaccurate, siloed models.
With a 3D CNNs deep learning model such as NCS, a single model (or generalized surrogate) can now be trained across multiple inputs in every project, using all the ~150 data points available. This ensures a more accurate predictive model and fewer team efforts in the data preparation phase.
This same model can now be reused for the following projects, with a very reduced requirement for additional data points (or without additional data points).
Conclusion
Data collection is often perceived as a challenge by engineering teams when it comes to deploying AI models at scale. However, a technical use case has shown that AI models by Neural Concept can assist automotive companies in overcoming this obstacle. With the benefits that Machine Learning derives from large datasets, it is crucial to collect enough data to train predictive models. But fear not, the path to success has been unveiled, and we invite everyone to join us on the high-speed train of AI predictive models!