Training Deep Learning Models Efficiently on the Cloud
In this article, we will present two case histories showing the achievements in building a scalable framework to train deep learning models and interact with them most efficiently. We will first introduce concepts from deep learning and the importance of training data, then explore how two relatively recent advances in computer science, namely GPUs and Cloud Computing, contribute to deep learning performance. Finally, we will present a case history of "Storing Data Efficiently on the Cloud" and a second one on "Improving the Training Speed of Deep Learning".
Introduction: Deep Learning, Machine Learning, Neural Networks and Their Training
Deep Learning is a subset of Machine Learning, a branch of AI reproducing some human brain functions such as pattern recognition and speech recognition. This is possible thanks to artificial neural networks and, more specifically, convolutional neural networks with techniques taken from computer vision.
Generative design technology is revolutionizing product design and manufacturing. This approach leverages the power of artificial neural networks and machine learning algorithms to go beyond simple flat 2D image recognition and generate and optimize design solutions in 3D space. With the help of 3D computational processes, designers can explore the vast design space and create innovative and efficient designs that meet their requirements.

At the heart of AI generative design are different types of artificial neural networks, such as recurrent neural networks and convolutional neural networks. These neural networks are trained on vast amounts of training data to develop deep learning skills. The skills are focused on identifying patterns and, ultimately, generating new design solutions. The training process involves feeding the neural network many examples, allowing it to learn from them and develop a deeper understanding of the design problem.

The training data for neural networks can come from various sources, including existing designs, simulation results, or the designer's preferences and constraints. The training process aims to enable the neural network to generate new design solutions optimized for the specified objectives and constraints.
The power of generative design technology lies in its ability to automate the design process and generate an immense number of potential design solutions. With the help of machine learning engineers, these neural networks can be trained to identify and prioritize the best solutions based on the specified objectives and constraints.
One type of neural network that is particularly well-suited for generative design is the convolutional neural network. A convolutional neural network is optimized for image and signal processing, making it ideal for design problems that involve visual elements.
Convolutional neural networks are trained to recognize image patterns, allowing them to generate aesthetically pleasing and functional designs.
Deep neural networks' learning capabilities have revolutionised the generative design field, allowing designers to explore new design possibilities and create innovative and efficient solutions. With the help of machine learning engineers, designers can train neural networks to optimize their designs for specific objectives, such as weight reduction, reduced manufacturing cost, or improved performance.
The training process for neural networks is iterative, with the output from each iteration serving as input for the next. This allows the neural network to continuously improve its understanding of the design problem and generate better and more optimized solutions.
As a summary of this section, generative design technology leverages the power of neural networks and machine learning algorithms to generate new design solutions. With the help of computational processes, designers can explore the vast design space and create innovative and efficient designs that meet their requirements. The training of neural networks is iterative, allowing them to continuously improve their understanding of the design problem and generate better and more optimized solutions. With the help of machine learning, designers can harness the power of deep learning to create designs optimized for specific objectives and constraints.
The Importance of Training Data
Training data are a crucial aspect of machine learning algorithms. Suffice it to say that machine learning allows software learning from data without being explicitly programmed. Instead, the software uses stored patterns and mathematical inferences to build predictive models. The quality and quantity of the data used to train these algorithms are crucial to their success in giving reliable and useful predictions.
When we refer to training data, we are talking about the dataset used to teach a machine-learning model how to recognize patterns and make predictions. The training data is used to identify patterns and establish relationships between different variables, which can then be used to predict new data. The more high-quality data fed into the model, the more accurate and reliable its predictions will be.
If training data are incomplete, inconsistent, or inaccurate, the model cannot learn the patterns and relationships. On the other hand, if the data is diverse, complete, and of high quality, then the algorithm can learn more effectively, leading to better predictions and results.
On top of quality, also quantity is important! One of the challenges of using training data is that it needs to be large enough to capture the range of patterns and relationships that exist within the data. In some cases, the amount of data required can be overwhelming, which is why the field of data science has emerged to help manage and analyze large datasets. However, even with the help of data science tools, it is essential to ensure that the data is of high quality.
There are many sources of training data, including public datasets, privately owned data, and data generated by the machine learning algorithm itself. The choice of training data can significantly impact the accuracy and effectiveness of the model, which is why it is important to choose the right data source for each problem.
One of the most significant challenges in machine learning is overfitting, which occurs when the model becomes too focused on the specific examples in the training data rather than learning the general patterns and relationships within the data. This can lead to poor performance when new data is introduced. To prevent overfitting, it is important to use diverse training data that covers a wide range of scenarios and situations.
Examples of the importance of training data include natural language processing and computer vision (CV).
- In natural language processing, training data is used to teach algorithms to recognize and interpret human language, leading to applications such as chatbots and voice assistants.
- Similarly, in CV, training data is used to teach algorithms to recognize objects and scenes, leading to applications such as image recognition and autonomous vehicles.
Transfer Learning
One of the key benefits of transfer learning is that it can significantly reduce the amount of data and computational resources required to train a deep neural network on a new task.
For example, in CV, transfer learning has significantly reduced the data required to train a deep neural network to achieve state-of-the-art performance.
The foundation of the transfer process is based on the observation that the representations learned by a deep neural network on one task can be used as a starting point for learning on a new task.
The Advent of GPUs and Cloud Computing
Training deep learning efficiently on the cloud involves several challenges: scalability, data storage and transfer, resource allocation, synchronization and parallelization, and deep learning model management.

Training Deep Learning on the Cloud - Advantages
Training deep learning on the cloud offers several benefits: scalability, access to large datasets, cost-effectiveness, flexibility, and collaboration. These benefits can make it a preferred option for many organizations, especially those with limited resources or those working on large-scale projects.
For example. training a deep learning predictor on the cloud can be more cost-effective than training models on the premises. Cloud providers can offer pay-as-you-go pricing models, which can help organizations avoid the upfront costs associated with purchasing and maintaining their own hardware. raining deep learning models on the cloud provides flexibility in terms of hardware and software resources. Cloud providers offer various options for hardware resources, such as different types of GPUs, and software resources, such as different deep learning frameworks.
What Are the Challenges of Training on the Cloud?
Several challenges arise when training a deep learning predictive model efficiently on the cloud.
Scalability Challenge
As deep learning models often require large amounts of data and computational resources, it can be challenging to scale neural network training to accommodate the dataset's size and the complexity of the deep learning model. This can lead to long training times and increased costs.

Data Storage and Transfer Challenge
Storing and transferring large amounts of data can be a significant challenge when training a deep learning model on the cloud. The data transfer process can be slow and costly, and it can be not easy to ensure the security and privacy of the data.
Resource Allocation Challenge
Allocating the appropriate resources, such as CPU, GPU, and memory, to neural network training can be challenging. It is important to choose the right resources to ensure the deep learning training process is efficient while avoiding over-allocation and unnecessary costs.
Synchronization and Parallelization Challenge
When training models on the cloud, it is important to synchronize the training across multiple machines and parallelise it to take advantage of the available resources. However, this can be challenging, as it requires careful coordination of the neural network training and can be affected by network latency and data storage.
Model Management Challenge
Managing a deep learning model trained on the cloud can be challenging, as it requires tracking the progress of the training, monitoring the performance of the models, and managing the storage and sharing of the deep learning model.
Case History: Storing Data Efficiently on the Cloud
With the deep learning predictive solution NCS, you can use 3D numerical simulations as input to train your deep learning model. If we take the example of aerodynamic simulations, these CFD simulation results are usually much larger files than images or text (a single result can reach several hundreds of GB). Hence storing a large amount of them can become an issue in the long term, as it would require regularly scaling up the hardware infrastructures accordingly.

Users might then face difficulties in streaming through the files to make relevant analyses, and it becomes a real limitation and bottleneck in the usage of deep learning for engineering applications. The issue was addressed at Neural Concept by evaluating different solutions over time.
NFS and Deep Learning
The Neural Concept's initial setup was an NFS (Network File System) solution.
NFS (Network File System) is a distributed file system protocol that allows a client computer to access files over a network as if they were stored locally. It was developed by Sun Microsystems and is commonly used in Unix and Linux environments. NFS allows a server to share directories and files that client computers can mount. The client can access the shared files and directories as if they were stored on the local machine.
It is very convenient because it allows accessing files the same way we would access them on the local storage of a machine and can be used by several users in a team. However, this solution does not scale well with the accumulation of data and the increasing number of experiments done by users simultaneously. Moreover, it can quickly become expensive.
As an alternative, we chose to store the data in a secure cloud environment, using FUSE libraries, allowing us to easily access data as if it was on a local computer while benefiting from the powerful and flexible cloud architecture.
Filesystem in Userspace (FUSE) and Deep Learning
Filesystem in Userspace, commonly known as FUSE, is an open-source software interface for Unix-like operating systems. It allows non-privileged users to create their own file systems without requiring kernel code changes.
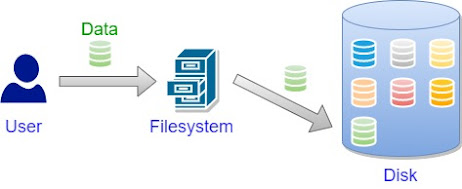
Traditionally, file systems in Unix-like operating systems are implemented as kernel modules. This approach has some drawbacks, including system administrators needing to load and unload modules, potential security issues, and difficulty developing and testing kernel code. FUSE provides an alternative by allowing developers to write file systems in user space.
FUSE implements a kernel module that bridges the user space and the kernel. The FUSE kernel module provides a set of APIs that user-space programs can use to create, modify, and delete files and directories. When a user space program accesses a file system implemented using FUSE, the FUSE kernel module intercepts the request and forwards it to the user-space program. The user-space program can then implement the file system operations using any programming language, including C, C++, Python, and more.
FUSE supports various file system operations, including creating and deleting files and directories, reading and writing file content, setting file attributes, and handling file system events such as mount and unmount.
FUSE has several advantages over kernel-based file systems, including ease of development and testing, flexibility in the choice of programming language, and the ability to implement new file systems without modifying the kernel. It also allows users to create file systems without root privileges.
FUSE is used in various applications, including cloud storage services, backup systems, and file synchronization tools.
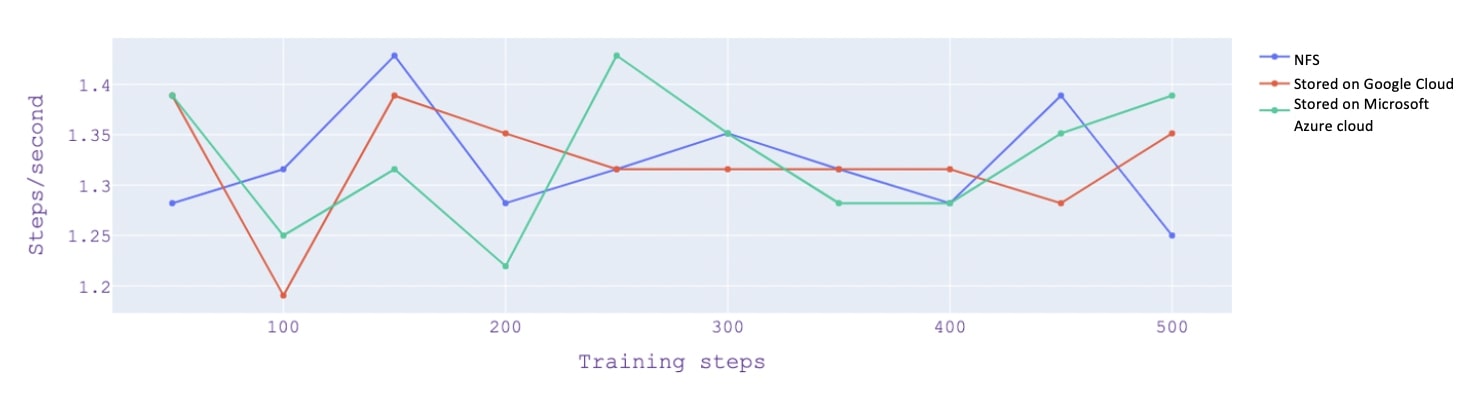
Using a FUSE library, users of NCS can train their models directly from secure cloud storage without any impact on computation speed, as it was benchmarked internally.
Case History: Improving the Training Speed of Deep Learning
The Role of CPUs in Deep Learning
GPUs, or Graphics Processing Units, are specialized processors designed to handle the complex calculations required for rendering images and videos. They have many small, efficient cores, allowing them to perform many calculations in parallel. This makes them particularly well-suited for deep learning, which involves performing large amounts of matrix computations.
Over the past years, the performance of GPUs has significantly improved, with newer models featuring more cores, higher clock speeds, and larger memory capacities. These improvements have greatly increased GPUs' processing power and made them more suitable for deep-learning applications.
Hence, the most modern GPUs can tackle complex physics-based deep-learning challenges and deal with (very) refined geometries.
Training and Improving Deep Learning Training Speed
With Neural Concept, we use 3D simulation data to train our models, which can be very heavy files if the simulation is extremely detailed. Most engineers would then tend to think that the main bottleneck when dealing with such data is the GPU itself, but it is not always the case.
The main reason for slow-down when training models on the cloud is not always the GPU itself, but it can also be the streaming of data to the GPU.
When training models on the cloud, data must be transferred from the storage location to the GPU for processing. This data transfer process can be a significant bottleneck, as it can be slow and costly. Network latency, bandwidth limitations, and dataset size can affect the data transfer. If the data transfer process is slow, it can limit the performance of the GPU and greatly slow down the training.
Indeed, this can drastically slow down training for large files, especially when the data is being fetched over the network from cloud storage.
It can then become a real limitation in using deep learning for engineering applications.
TensorFlow Data API
For the previous reasons, we used the cache functionality of TensorFlow data API.
TensorFlow is an open-source deep learning library for numerical computation and deep learning.
TensorFlow Data API is a collection of functions and classes in the TensorFlow library that provide a high-level interface for loading, preprocessing, and transforming data.
The cache functionality of the TensorFlow Data API allows for caching the results of data loading and preprocessing steps to disk so that the data can be easily reloaded without having to repeat expensive computations ("caching" refers to saving the processed data in temporary storage such as disk or memory, so that it can be easily reloaded and used later without having to repeat the data processing steps).
During training, we cached the dataset to a local SSD disk, allowing very efficient data retrieval. Caching data can be very efficiently and rapidly accessed as it is stored locally. After the initial pass over the dataset and the first iterations, the dataset gets cached, and subsequent iterations go much faster, as shown in the figure.
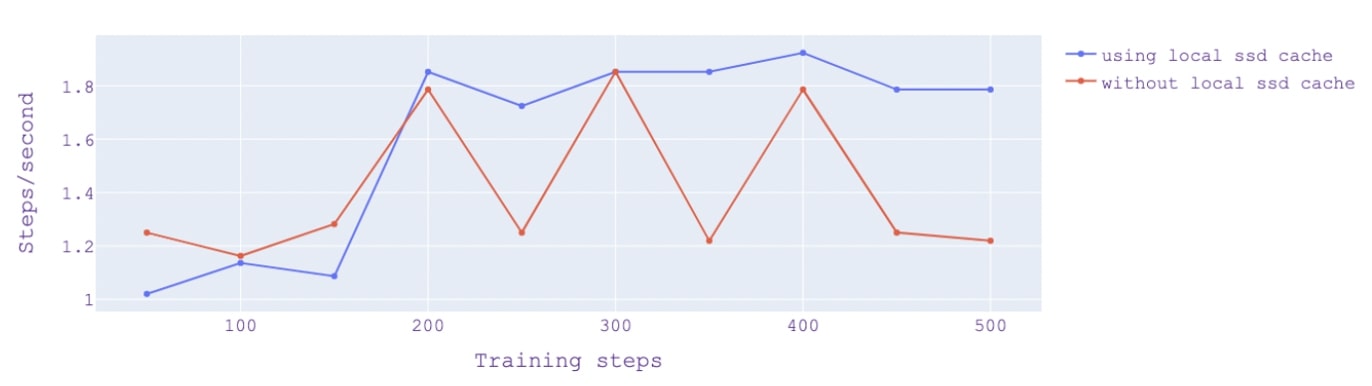
The graph shows that after the initial 150 steps (after which data has been cached to the local SSD Disk), the training speed increases and remains steady when using the cache.
This enables the engineers using NCS to perform various experiments very efficiently, even when dealing with large datasets or complex simulations.
Note:
- A cache is where data is stored temporarily to be accessed more quickly in the future. In computing, this means storing frequently used data that can be accessed more quickly than stored on a regular hard drive or in the cloud.
- An SSD (Solid State Drive) is a storage device that uses flash memory to store data faster than traditional hard drives.
- A local SSD cache refers to using an SSD as a cache for frequently accessed data on a local computer or server. This means that the most frequently accessed data is stored on the SSD, which can be accessed more quickly than if stored on a regular hard drive. This can help to improve the overall performance, as frequently accessed data can be retrieved more quickly.
Conclusion - Summary
Deep learning with convolutional networks has recently combined data with mathematical representations of human brain functions such as object detection, giving more than human-level performance in specific tasks.
While pure computing power is important, several aspects of IT infrastructure must be solved.
Neural Concept has been very active in this field, with success stories to be shared.
We have reviewed two technical case histories, the former on storing data more efficiently on the cloud and the second on improving training speed with a local SSD cache.


.jpg)